 Image credit: García-García et al. (2024)
Image credit: García-García et al. (2024)
Abstract
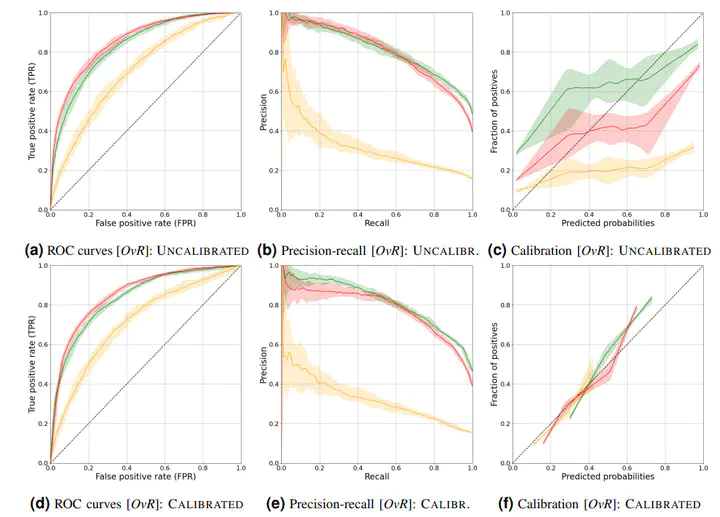
Objective: To study the suitability of cost-sensitive ordinal artificial intelligence-machine learning (AI-ML) strategies in the prognosis of SARS-CoV-2 pneumonia severity. Materials & methods: Observational, retrospective, longitudinal, cohort study in 4 hospitals in Spain. Information regarding demographic and clinical status was supplemented by socioeconomic data and air pollution exposures. We proposed AI-ML algorithms for ordinal classification via ordinal decomposition and for cost-sensitive learning via resampling techniques. For performance-based model selection, we defined a custom score including per-class sensitivities and asymmetric misprognosis costs. 260 distinct AI-ML models were evaluated via 10 repetitions of 5×5 nested cross-validation with hyperparameter tuning. Model selection was followed by the calibration of predicted probabilities. Final overall performance was compared against five well-established clinical severity scores and against a ‘standard’ (non-cost sensitive, non-ordinal) AI-ML baseline. In our best model, we also evaluated its explainability with respect to each of the input variables. Results: The study enrolled n=1548 patients: 712 experienced low, 238 medium, and 598 high clinical severity. d=131 variables were collected, becoming d′=148 features after categorical encoding. Model selection resulted in our best-performing AI-ML pipeline having: a) no imputation of missing data, b) no feature selection (i.e. using the full set of d′ features), c) ‘Ordered Partitions’ ordinal decomposition, d) cost-based reimbalance, and e) a Histogram-based Gradient Boosting classifier. This best model (calibrated) obtained a median accuracy of 68.1% [67.3%, 68.8%] (95% confidence interval), a balanced accuracy of 57.0% [55.6%, 57.9%], and an overall area under the curve (AUC) 0.802 [0.795, 0.808]. In our dataset, it outperformed all five clinical severity scores and the ‘standard’ AI-ML baseline.
Type
Publication
IEEE Journal of Biomedical and Health Informatics
Joaquín Martínez-Minaya
Associate Professor in Statistics and Optimization
My research interests include Spatio-temporal Bayesian models using INLA and Stan, and Compositional Data methods